La captura de movimiento (mocap abreviado del inglés motion capture) es el proceso de grabar el movimiento de un objeto o personas para generar un modelo 3D que pueda ser ejecutado por la computadora, estos son clasificados en outside-in, inside-out e inside-in dependiendo de las fuentes de captura y de donde son puestos los sensores o marcadores.
- Los sistemas outside-in usan sensores externos para capturar los datos de fuentes colocadas en partes del cuerpo, un ejemplo de esto son los dispositivos de rastreo basados en cámaras en el que las cámaras son los sensores y los marcadores reflectantes son las fuentes
- Los sistemas inside-out son sensores que se ponen en el cuerpo que recolectan fuentes externas, un ejemplo de esto son sistemas electromagnéticos cuyos sensores se mueven en un campo electromagnético generado externamente
- Los sistemas inside-in tienen tanto los sensores como las fuentes en el cuerpo.
Los sistemas ópticos de captura de movimiento son un método muy preciso para capturar ciertos movimientos, es un sistema basado en una computadora que controla la entrada de las cámaras, las cuales son sensibles a la luz para crear las representaciones digitales. Este es el sistema con el que cuenta la universidad del cual se hablara más adelante, primero hay que tratar con el problema del posicionamiento de las cámaras.
Posicionamiento de cámaras
Un problema que surge comúnmente en la captura de movimiento es el posicionamiento adecuado de las cámaras. Para saber las coordenadas de un punto de interés, es necesario que este sea visto por al menos dos cámaras (o más, dependiendo del sistema). Así, es de interés poder calcular las posiciones que maximicen la visibilidad de puntos.
Cómo parte del proyecto, consultamos el paper Optimal Camera Placement for Motion Capture Systems. Dicha publicación propone una nueva manera de calcular posiciones óptimas para las cámaras en un entorno para la captura de movimiento.
Métrica de error basada en oclusión
La métrica de error basada en oclusión presenta una forma de medir la visibilidad de un punto objetivo específico por al menos dos cámaras, para un conjunto de cámaras, cuando se presenta oclusión dinámica.
Para tomar en cuenta la gran mayoría de oclusores posibles, se considera un plano vertical que gira alrededor del punto objetivo. Así, entre todos todos los ángulos entre $0$° y $360$° que puede girar este plano respecto al punto, habrá ciertos intervalos de ángulos en los cuáles el punto no es visible por al menos dos cámaras. La métrica calcula la suma de las longitudes de estos intervalos. Informalmente, esta corresponde a la “suma de ángulos” en los cuáles no es visible el punto objetivo, y nos interesa minimizar esta cantidad.
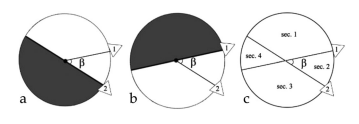
En la imagen anterior, observamos que la visibilidad del punto sólo cambia cuando el plano cruza el vector de la vista de una cámara. Notamos también que si existen $n$ cámaras, sus vectores de vista generan $2n$ regiones (es decir, intervalos de ángulos) de interés; por ejemplo, en la imagen, dos cámaras dividen el círculo centrado en el punto de interés en $4$ partes.
Además de esto, consideramos una restricción de triangulación para un par de cámaras: aunque ambas sean capaces de ver el punto de interés; sólo se toman en cuenta si el ángulo entre sus vectores de vista está entre 40° y 140°. Esto es porque si el ángulo es muy grande o muy pequeño, el error numérico al intentar triangular el punto es también muy grande. Asimismo, se descartan las cámaras si el punto está mas allá de el rango efectivo de estas.
La métrica anterior se puede calcular, en pseudocódigo, con el siguiente algoritmo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#n - cantidad de camaras
#C[1..n] - posiciones de las cámaras
#S[1..2n] - las longitudes de las regiones que generan
los vectores de vista de las camaras
#Cf[] - posiciones de cámaras en C frente al oclusor
#flag - es verdadera si en la región,
el punto es visible por al menos dos cámaras
Q - suma de las regiones en las que no es visible el punto.
por al menos dos cámaras.
-----------------------------------------------------
calcular S
para i = 1 hasta 2n:
calcular Cf a partir de C y S[i]
flag = false
para j = 1 hasta longitud(Cf):
para k = j + 1 to longitud(Cf):
si Cf[j] y Cf[k] satisfacen la
restricción de triangulación:
flag = true
break
si flag = false:
Q += S[i]
regresa S[i]
Recocido simulado
Para aplicar la métrica anterior en el cálculo de posiciones óptimas, se utiliza el método de recocido simulado. Este es un método muy general que, de manera heurística, busca una aproximación al mínimo o máximo global de una función.
Este algoritmo considera una temperatura. Se inicia en una estado arbitrario; y se consideran varios estados siguientes válidos. Si alguno de estas mejora la función que queremos minimizar (o maximizar), cambiamos a este estado. De otra manera, aunque el siguiente estado empeore la función, con cierta probabilidad que depende de la temperatura, se cambia a este estado.
La temperatura está definida de tal manera que, entre más alta, es más probable que se tome una nueva posición. Así, se inicia con una temperatura alta, la cual va disminuyendo conforme pasa el tiempo. El objetivo de esta es “escapar” mínimos locales; es decir, estados que no son óptimos, pero que están rodeados de estados peores.
Volviendo al problema de posicionamiento de cámaras, consideramos los estados como el conjunto de posiciones de las cámaras, y la función a minimizar será una modificación sobre la métrica de error basada en oclusión. Dado un estado, tiene sentido considerar a los siguientes estados posibles como aquellos que cambian la posición de exactamente una cámara.
La primera modificación necesaria es considerar múltiples puntos. Supongamos que estos son $p_1,\ldots,p_m$. Entonces denotemos $Q_i$ como la métrica descrita antes, con el punto $p_i$ como objetivo. Nos interesa minimizar
\[f = \sum_{i = 1}^m Q_i.\]Esto aún genera un problema. ¿Por qué? La métrica original no incentiva el poner una cámara en una región que no contenga ninguna cámara: al pasar de 0 cámaras a 1 cámara en la región, esta región sigue sin contener al menos un par de cámaras, así que su longitud se sigue considerando. Más aún, este cambio empeora la métrica si la región de la cual se toma la cámara a mover contiene sólo un par de cámaras.
Para esto definimos $\theta$ como un penalty asignado a puntos que no son visibles por un par de cámaras. Consideremos un punto $p_i$, y $C_i$ como el conjunto de puntos cuyos vectores de vista ven a $p_i$. Entonces, definimos el valor $E_i$ como la nueva métrica, dada por:
\[E_i = \begin{cases} 360 + \theta & |C_i| = 0\\ Q_i & |C_i| > 0. \end{cases}\]Finalmente, queremos minimizar $f$, redefinida como
\[f = \sum_{i=1}^m E_i,\]usando recocido simulado. El paper original sugiere usar $\theta = 360$ para obtener mejores resultados.
El sistema de Motion Capture en CIMAT - Guía de uso
El procedimiento anterior, aunque interesante en teoría, no es aplicado en CIMAT en la actualidad. Para el sistema de CIMAT, se cuenta con la siguiente guía:
Calibración
Se utiliza el software Motion, de Optitrack; a través de este se hará la calibración.
Preparar el ambiente
Se deben bloquear o remover los objetos que puedan interferir con las cámaras; ya sea ventanas abiertas, superficies reflejantes, luces infrarojas, marcadores, etc.
Camera Masking
Se cubren las fuentes de luz restantes; incluyendo la interferencia de las cámaras entre sí. Esto se puede hacer con la opción de Auto-Masking, “Block-Visible”. Esta esconde de manera automática los puntos brillantes. Otra opción es cubrirlas manualmente con herramientas de selección.
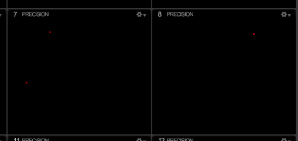
Wanding
Se debe presionar el botón “Start Wanding”; el motor de calibración comenzará a grabar samples cuando detecte la varita de calibración. Se debe cubrir con los marcadores de la varita todo el volumen que detecten las cámaras. El motor de calibración se mostrará verde cuando tenga suficientes samples. Es recomendable seguir el proceso hasta cubrir suficiente área.

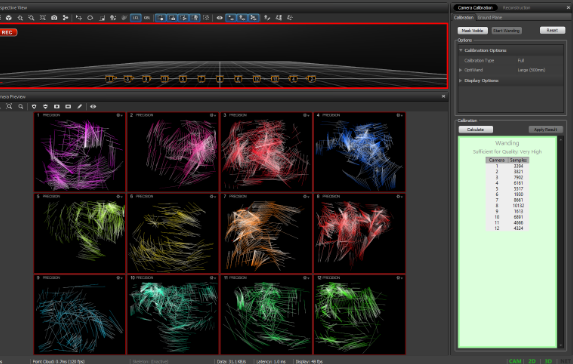
Calculation
Tras hacer el “Wanding”, el proceso de cálculo se hace presionando el botón “Calculate” del panel “Calibration”. Solo es necesario esperar a que el proceso converja a una solución, pero se puede dejar continuar para obtener calibración más precisa. Se puede monitorear el proceso con el visor 3D, que se ve como sigue:
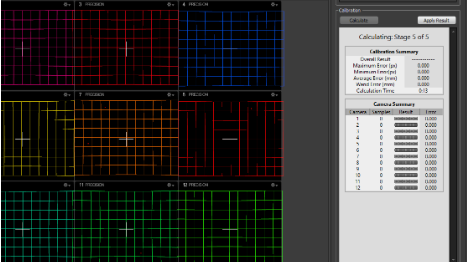
Aplicar los resultados
Solo es necesario presionar el botón “Apply Results”. Saldrá un aviso de guardar los resultados del “Wanding”. Tras guardar, es posible escoger el plano del suelo con el artefacto que determina el plano Z.
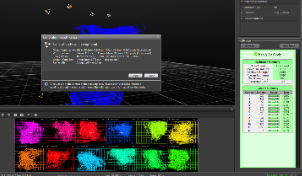

Verificar los resultados
Ejecutar la herramienta “Volume Accuracy Tool” para verificar la calidad de la calibración. Se mide la desviación entre las longitudes que se midieron y las reales de la varita de calibración.
Sesión de Grabación
Suit Up
Ponerse el traje de la talla adecuada, lo más ajustado posible; esto previene que los marcadores se muevan mucho respecto al cuerpo.
Los marcadores se deben colocar en lugares específicos (Marker Sets). El estándar, “Baseline” consiste en 37 marcadores y se puede ver en “Views”->”Sekeletons”->”Choose Markerset”.
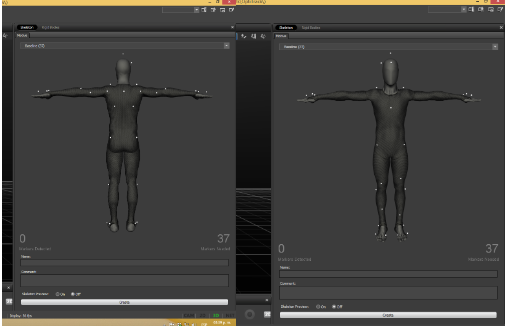
Definir un esqueleto
Hacer clic en “Layout”->”Create”. El actor para el cual se vaya a definir el esqueleto se debe colocar en el centro del volumen de grabación con los marcadores de el Marker Set adecuado.
El actor se debe colocar en “posición T” frente a las cámaras, y se mostrará un modelo cuando el actor este en la posición correcta.

Grabar datos
Tras calibrar y definir esqueletos, seleccionamos “Layout”-> “Capture” para acceder a las opciones de grabación. Seleccionar el botón rojo de grabación y comenzar a capturar los datos 3D.
El panel de timeline funciona de manera similar que un software de grabación de audio o una cámara de video. Con el botón comenzamos a grabar en una nueva toma. El panel (botón de comenzar a grabar, detener, etc) es similar a cualquier otro software de grabación.
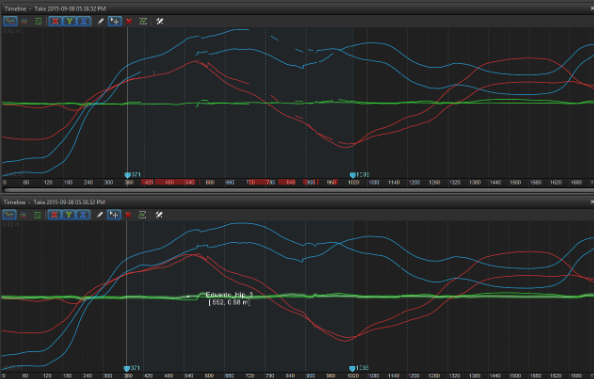
En la sección “Take” se da el nombre a la toma. También se muestra información como el tiempo grabado, la latencia y los “frames per second”.
Si el esqueleto pierde la forma, se puede calibrar posicionandose de nuevo en posición de T.

Sesión de Edición
Abrir un proyecto existente y seleccionar “Layout”->”Edit”. Escoger alguna toma (“Takes”) para obtener la información de marcadores de esta.
En el panel “Project”, la sección “Assets” muestra los esqueletos y cuerpos rígidos de la toma. Al seleccionar algún esqueleto, encontramos sus marcadores, y se pueden seleccionar para Editar.
Eliminar marcadores de ruido
Para cada esqueleto y cuerpo rígido se deben eliminar los marcadores que aparezcan como “Undefined”.
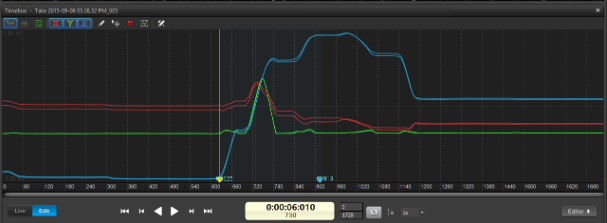
Seleccionar animación deseada
En el editor de “timeline” se selecciona la sección de grabación para trabajar, como se ve en la imagen:
Fill gaps
Seleccionamos marcadores con “gaps” (huecos) en sus gráficas; estos se van a llenar escogiendo con alguna interpolación.
Esto se puede hacer en “Fill Gaps” del panel “Edit Tools”. Seleccionamos el tamaño máximo de los gaps que llenaremos con una interpolación, así como el tipo de interpolación a usar (ej. Max. Gap Size = 10) que utilizaremos (ej. Interpolation = Cubic). Con la opción “Fill Selected” se llenan los gaps seleccionados.